你有没有想过,如何在家里的电脑上搭建一个属于自己的大数据处理平台呢?没错,就是那个大名鼎鼎的Hadoop!今天,我就要带你一起走进Hadoop单机部署的世界,让你轻松掌握这个大数据利器。
Hadoop单机部署,顾名思义,就是在你的电脑上搭建一个Hadoop环境。这个过程虽然简单,但却是了解Hadoop分布式存储和处理的基础。别看它简单,但其中的学问可不少哦!
在开始之前,你需要准备以下几样东西:
1. 操作系统:推荐使用Linux系统,如CentOS、Ubuntu等。
2. Java环境:Hadoop是基于Java开发的,所以你需要安装Java环境。推荐使用Java 8或更高版本。
3. SSH:SSH是一种安全协议,用于远程登录和文件传输。在Hadoop单机部署中,SSH用于启动和停止Hadoop服务。
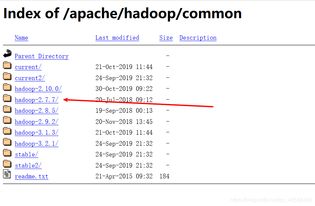
1. 下载Hadoop:从Hadoop官网下载适合你操作系统的Hadoop版本。例如,你可以下载Hadoop-3.4.0.tar.gz。
2. 解压Hadoop:将下载的Hadoop压缩包解压到你的电脑上。例如,你可以解压到/usr/local/hadoop目录下。
3. 配置环境变量:在终端中执行以下命令,配置Hadoop环境变量。
```bash
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
4. 配置SSH:为了方便后续操作,你需要配置SSH免密码登录。在终端中执行以下命令:
```bash
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
1. 编辑配置文件:Hadoop的配置文件位于Hadoop安装目录下的etc/hadoop目录下。你需要编辑以下配置文件:
- core-site.xml:配置Hadoop运行时的基本参数,如HDFS的文件系统名称、HDFS的存储路径等。
- hdfs-site.xml:配置HDFS的参数,如副本因子、文件存储路径等。
- mapred-site.xml:配置MapReduce的参数,如MapReduce的运行模式、MapReduce的输出格式等。
- yarn-site.xml:配置YARN的参数,如资源管理器、应用程序管理器等。
2. 格式化HDFS:在终端中执行以下命令,格式化HDFS。
```bash
hdfs namenode -format
1. 启动NameNode:在终端中执行以下命令,启动NameNode。
```bash
start-dfs.sh
2. 启动ResourceManager:在终端中执行以下命令,启动ResourceManager。
```bash
start-yarn.sh
3. 启动HistoryServer:在终端中执行以下命令,启动HistoryServer。
```bash
mr-jobhistory-daemon.sh start
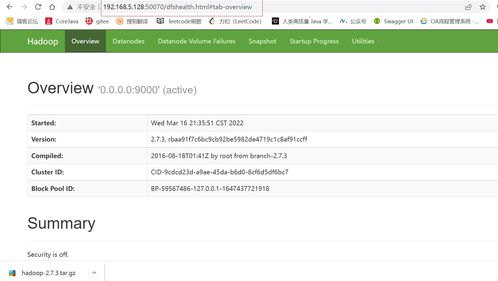
1. 查看HDFS Web界面:在浏览器中输入http://localhost:50070,查看HDFS的Web界面。
2. 查看YARN Web界面:在浏览器中输入http://localhost:8088,查看YARN的Web界面。
通过以上步骤,你已经在你的电脑上成功搭建了一个Hadoop单机环境。虽然这只是Hadoop的一个简单应用,但相信这对你了解Hadoop分布式存储和处理会有很大的帮助。接下来,你可以尝试使用Hadoop处理一些简单的大数据任务,比如单词计数、日志分析等。祝你学习愉快!